VID 和 Rank
通过这节课,大家会了解 NebulaGraph 中 VID 和 Rank 两个概念。此外,还会帮助大家巩固在属性图课程中介绍的标签(Tag)和关系类型(Edge Type)的概念。
VID
这里我们用 Joe 小伙伴为大家更形象的展示 VID 的概念。Joe 是一个篮球运动员,我们为他运动员的身份创建一张表,表名为player。
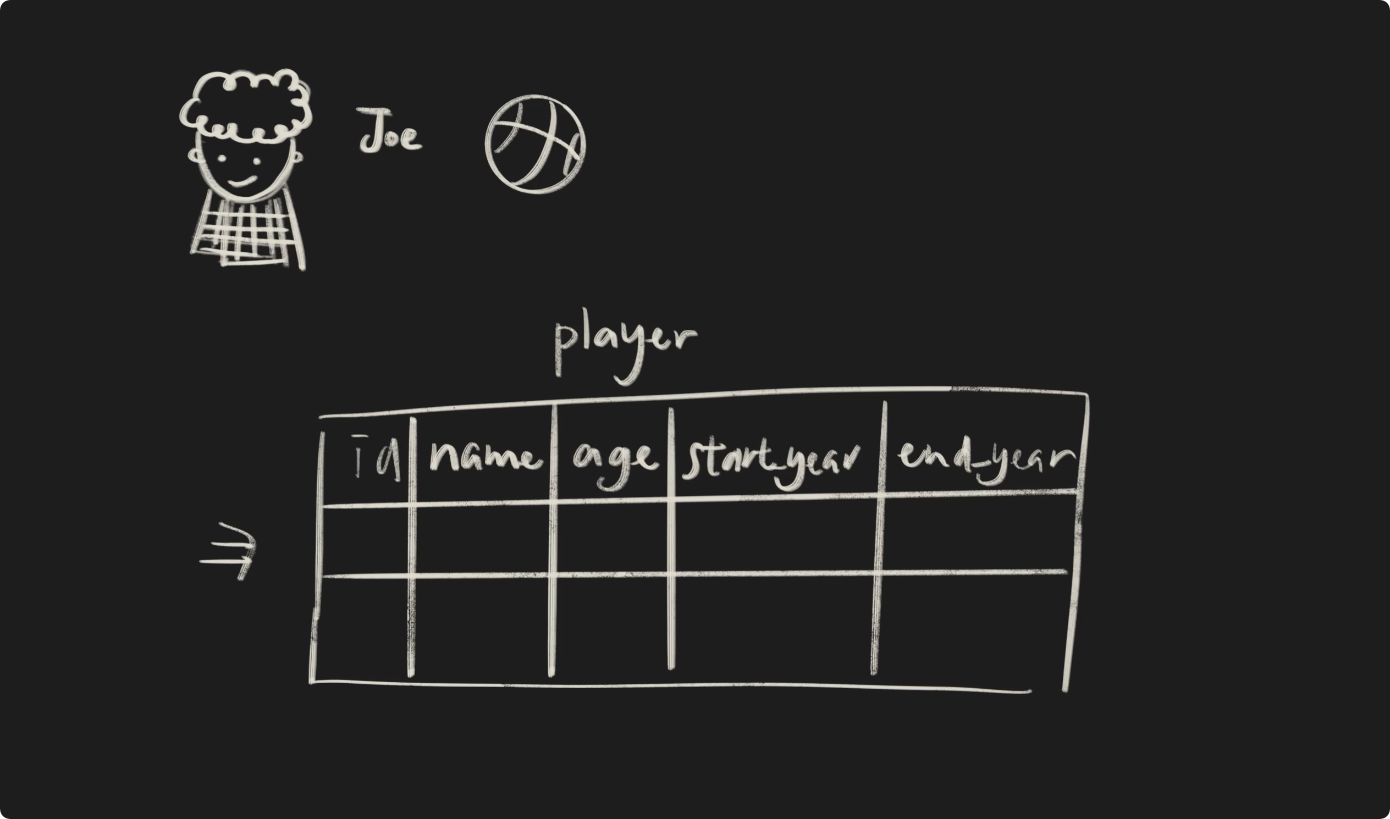
插入他的姓名、年龄、加入球队和退出球队的时间。
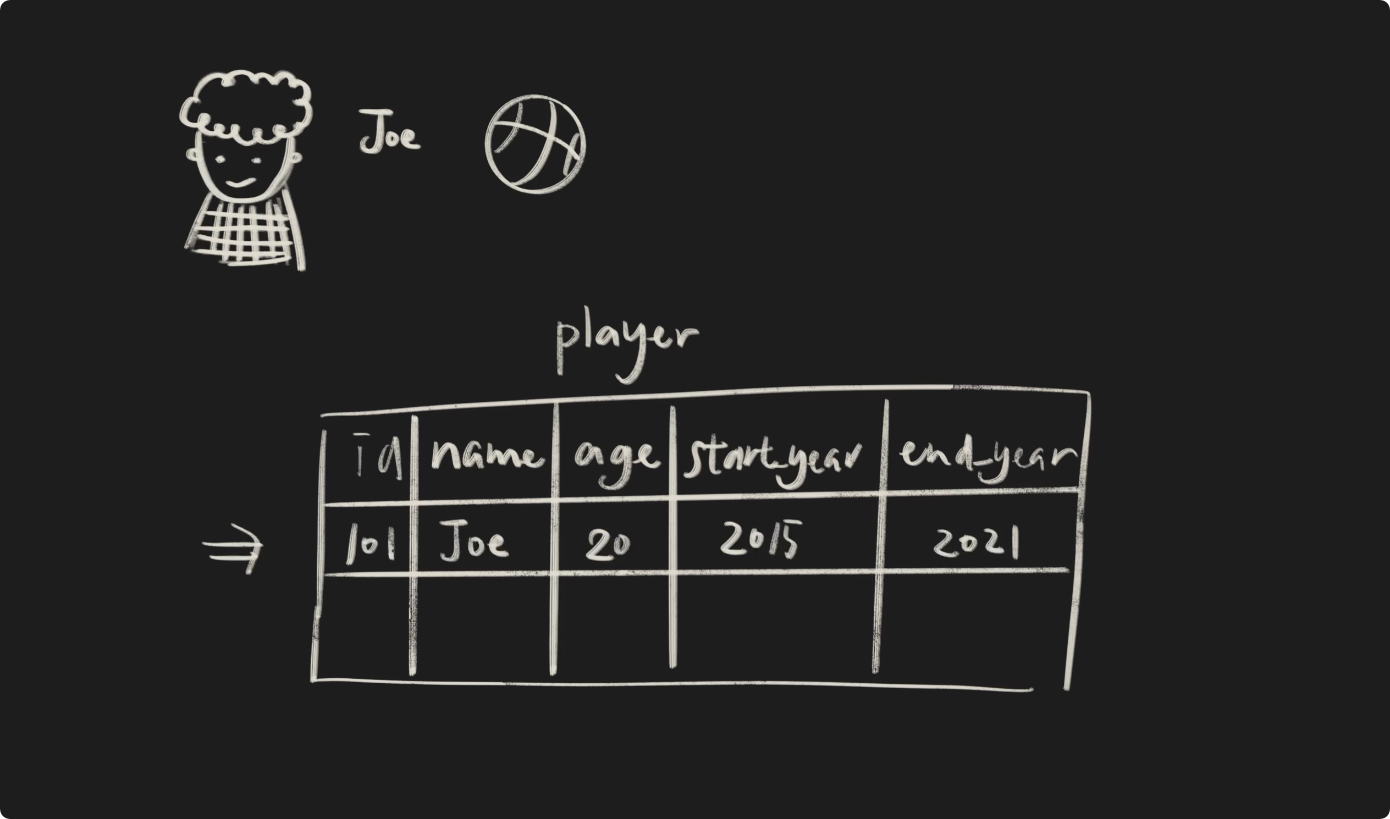
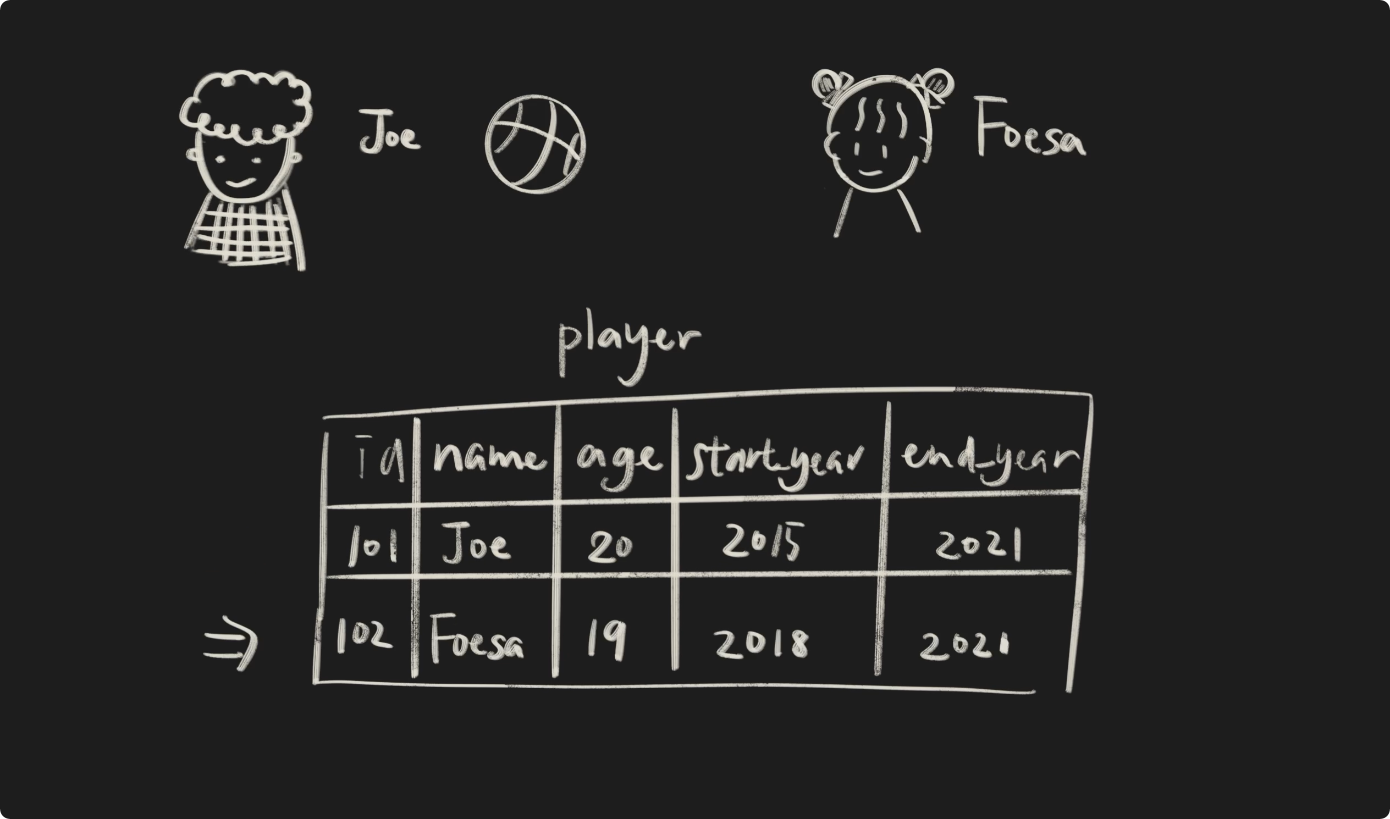
当然在这个表下,也可以插入同是运动员的foesa的数据。
为了让大家更好的理解 NebulaGraph 的不同,我们给出使用 SQL、Nebula Graph、Neo4j 三种不同方式创建及插入数据的语句。

使用 SQL 创建表时,你需要用
PRIMARY KEY指定主键以确定id为点的唯一标识。在使用 Neo4j 语句时,不需要创建
player表中的 ID,系统会自动分配一个内部 ID 用来唯一标识记录。在 Nebula Graph 中,我们定义了点的唯一标识 VID,也可以理解成主键。需要注意的是与 Neo4j 不同,VID 必须在用户插入点时手动创建,系统不会自动生成。黑板上给出的语句中,
INSERT VERTEX中的VALUES 101,就选定了 ID 作为 VID,插入了 Joe 的信息。换句话来说 VID 就像是人的身份证号,用来唯一标识人的身份一样。
每个图空间仅支持一种 VID 数据类型,创建图空间时,可以预先设置 VID 的数据类型,可选值为FIXED_STRING(<N>)和INT64,设置后无法更改。
在 NebulaGraph 一个图空间内,VID 数据类型设置之后无法修改,除非重建该图空间。
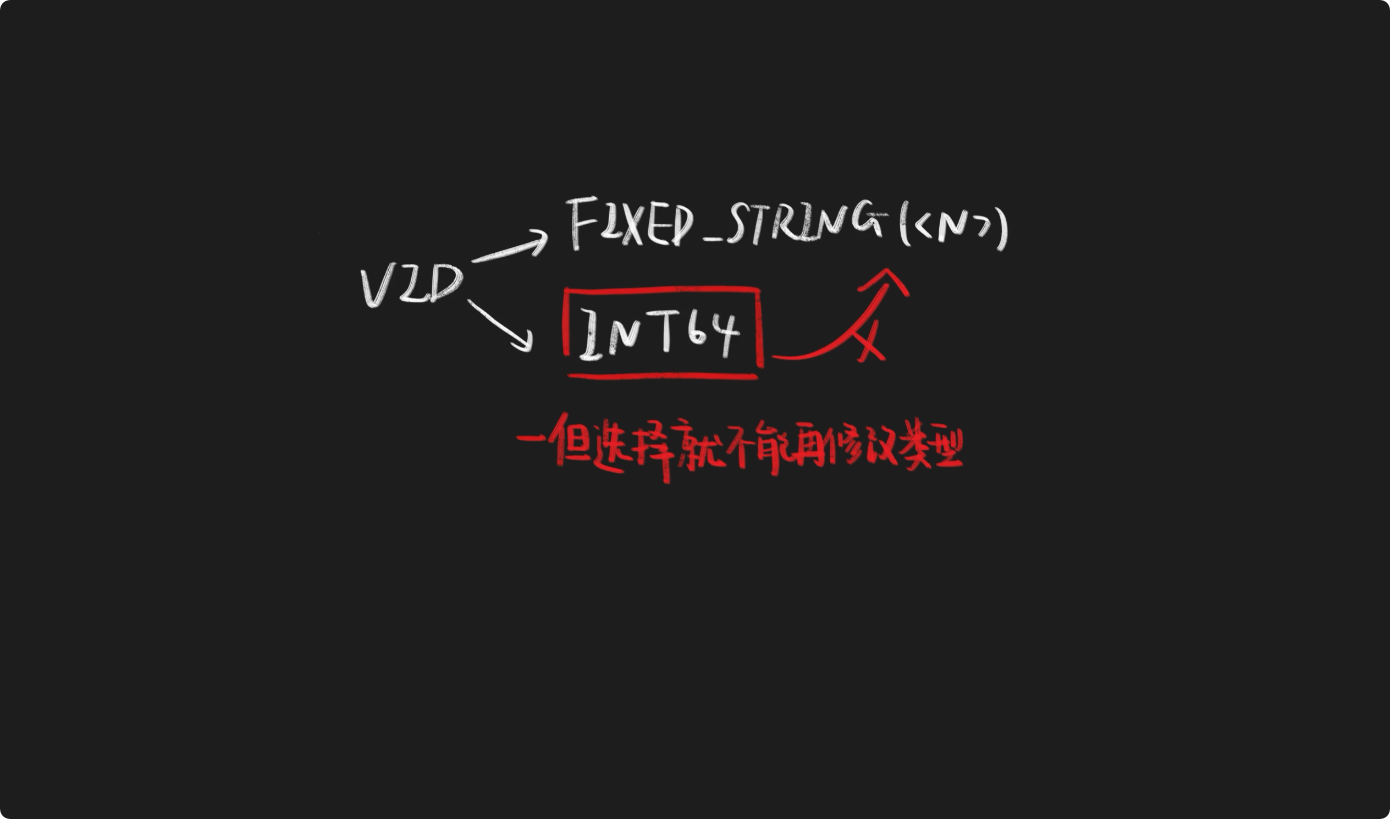
FIXED_STRING(<N>)表示数据类型为定长字符串,长度为N不足时会填充,超出长度会报错。INT64表示数据类型为 64 位整数。在这里我们建议你在创建FIXED_STRING(<N>)类型 VID 时,选择大于等于 VID 长度的最大值。
Joe 是个运动员,同时也是一名学生,他也在student表中。而 Foesa 已经毕业啦,所以并不在student表中。这里的player表和student表相当于 nGQL 中 Tag。对于 Joe 来说,不同的身份,意味着他有着不同的标签,而player表中的name、age、start_year、end_year,都是标签player的属性。
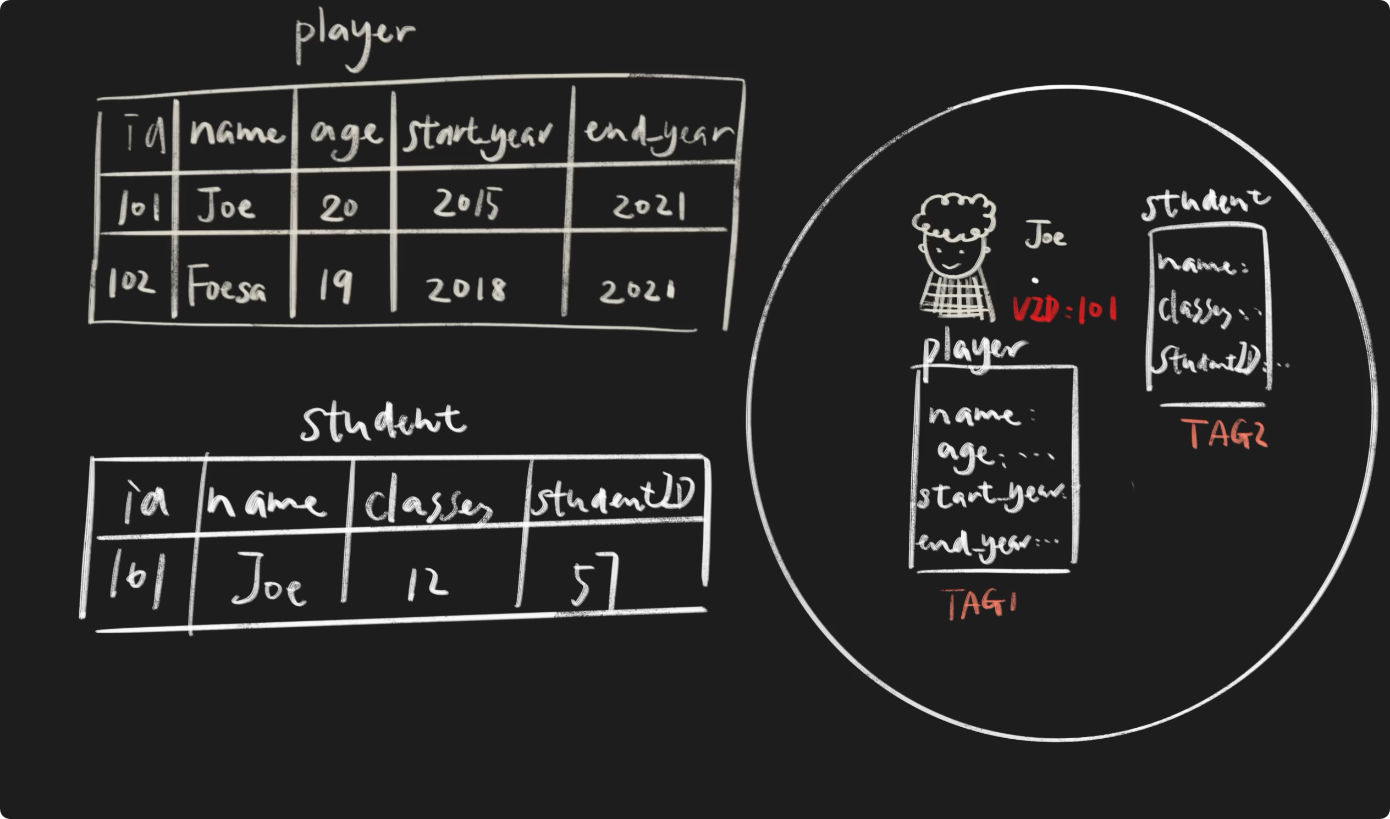
对于 VID 为101的 Joe 来说,重新插入创建另一个player,就会将之前player Tag 中的内容覆盖,以最新的插入为准。
相信到这里,大家已经明白 VID 和 Tag 之间的关系了,接下来我们介绍 Edge Type 和 Rank。
Rank
Joe 小伙伴和 Foesa 是好朋友,他们经常通话,我们创建一个名字为call的边类型 Edge Type。
需要注意的是,每个图空间内的边类型名称不能重复,名称设置后无法修改。
在call表中的time和continue_time就是边类型call的属性,它们有着不同的数据类型。
这里,我们插入他们的多次通话的数据。
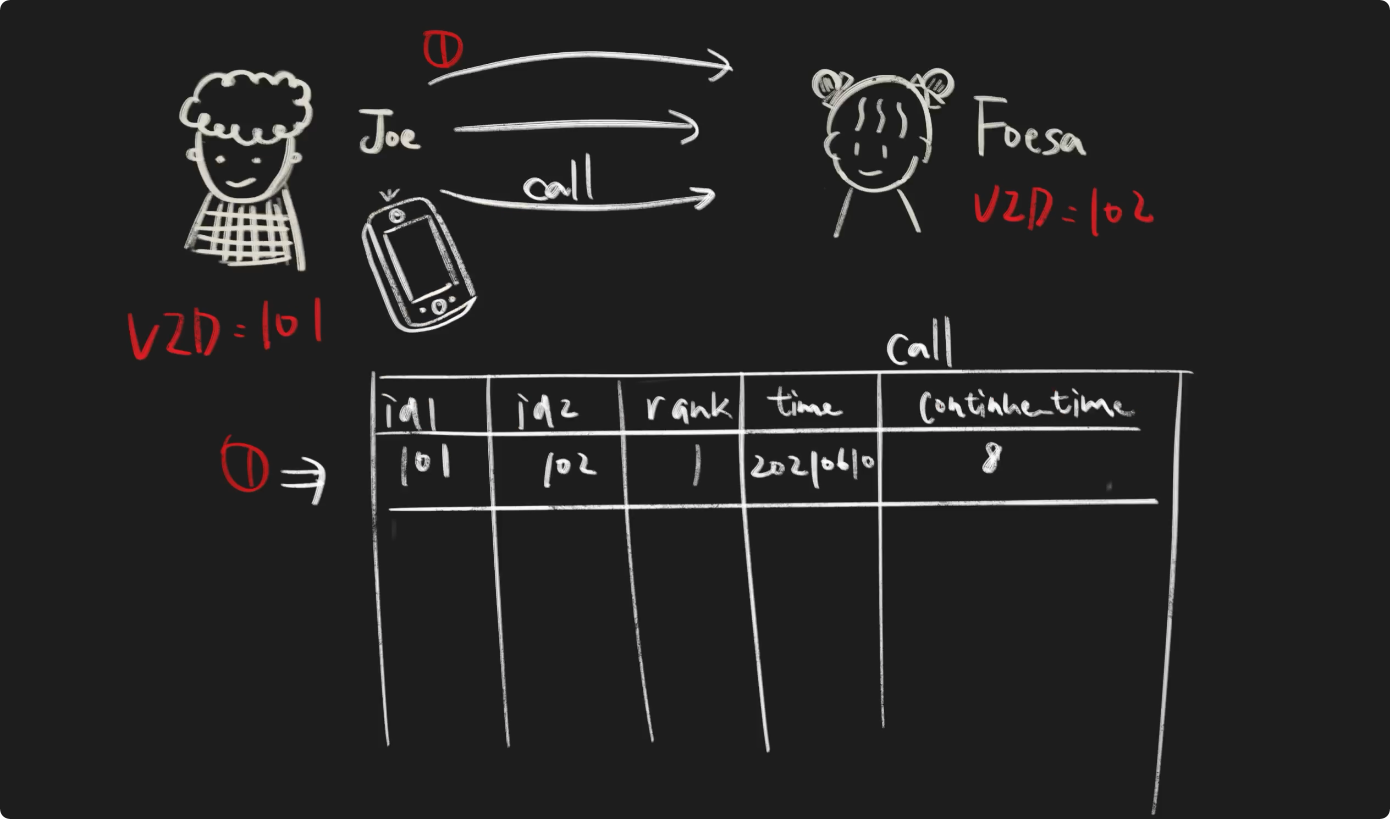
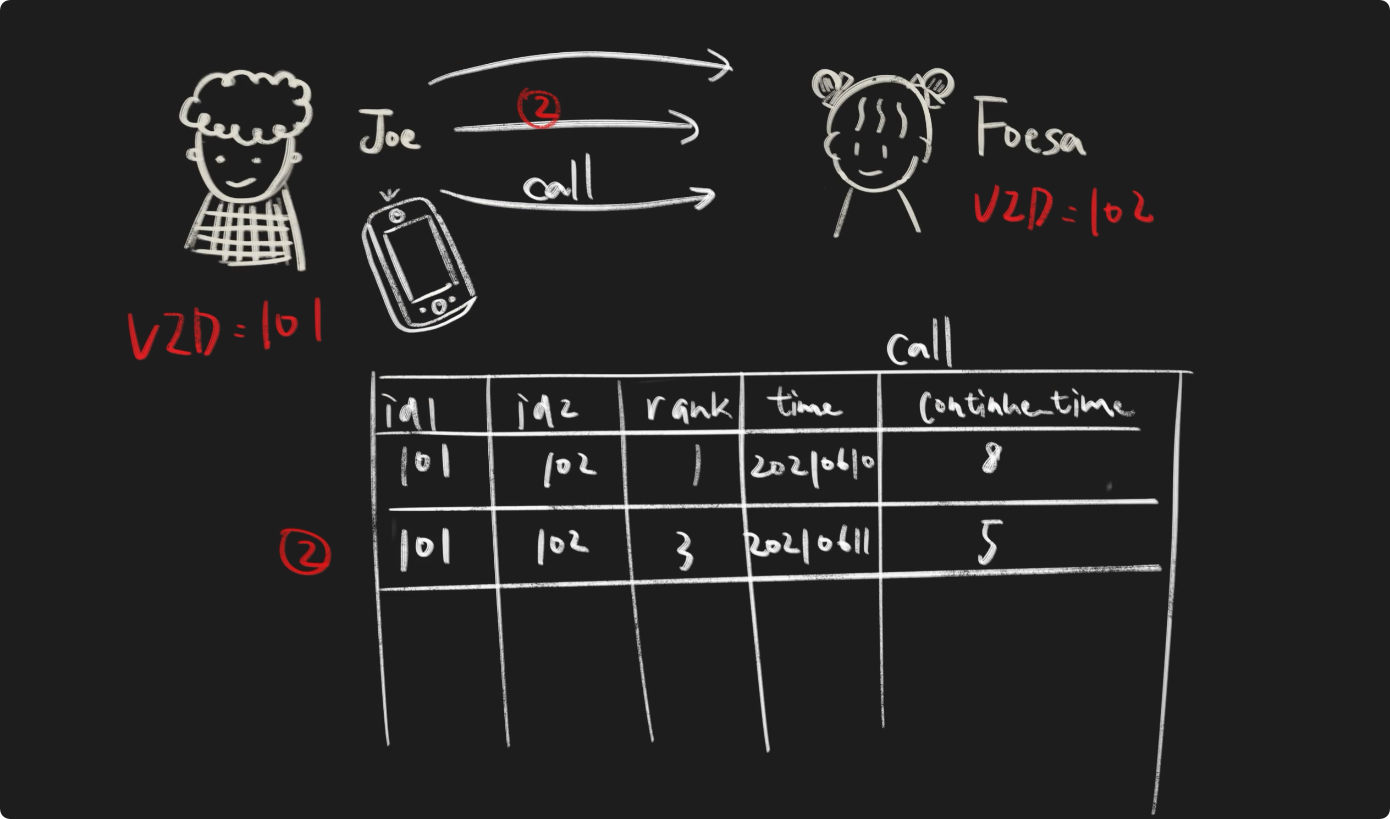
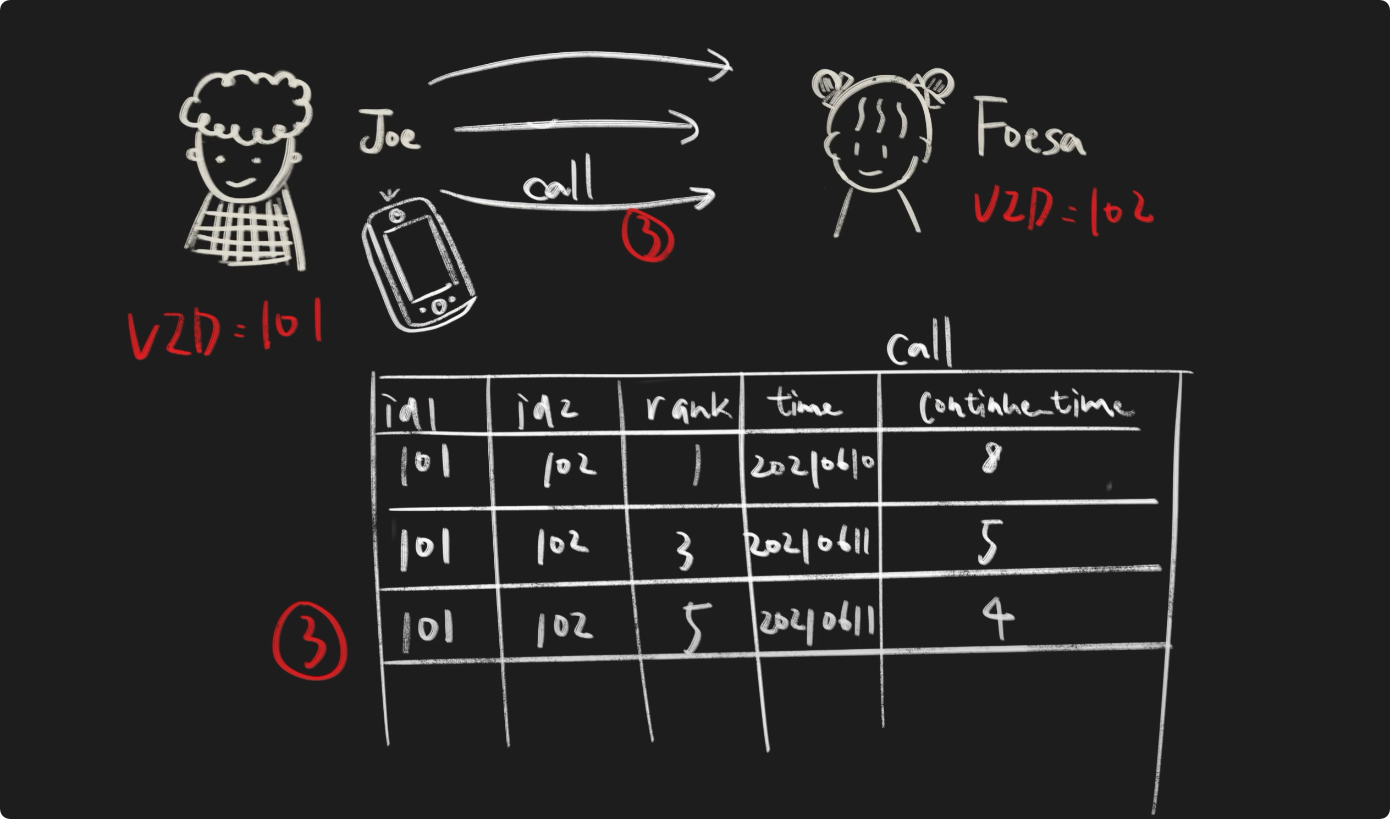
我们可以看到,起始点为101,目的点为102,边类型都为call的三条边。在 NebulaGraph 中,为了让用户可以更好的区分边类型名称、起始点、目的点都相同的边,我们引入了 Rank 的概念,没有指定时,默认 Rank 值为 0。因此我们可以使用(边类型,起始点,目的点,Rank)唯一确定一条边。
这里相信大家已经明白 NebulaGraph 中这些独特的概念啦。
课堂小测试
1、关于 VID 的描述,不正确的有