NebulaGraph 架构
架构概述
NebulaGraph 是存储与计算分离的架构,由三种服务构成:Graph 服务、Meta 服务和 Storage 服务。下图展示了 NebulaGraph 集群的经典架构。
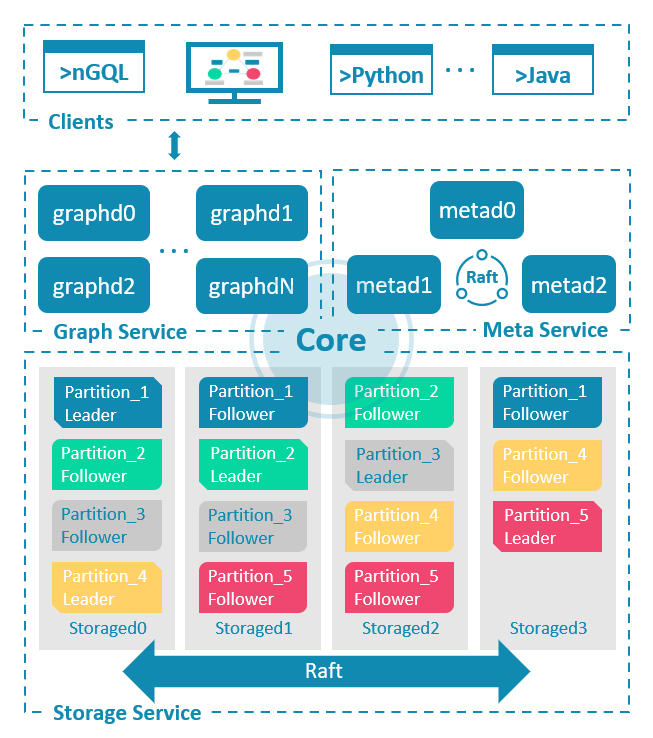
通过客户端将请求发送给 Graph 服务,Graph 服务处理之后再交由 Meta 服务或 Storage 服务执行,最后将结果返回给客户端。
接下来简单介绍这三种服务。
Graph
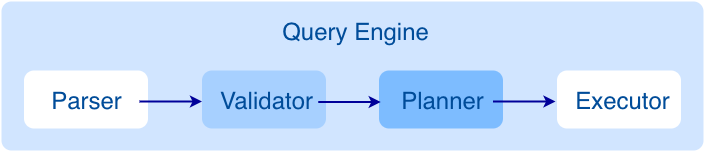
Graph 服务负责处理计算请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行。
Meta
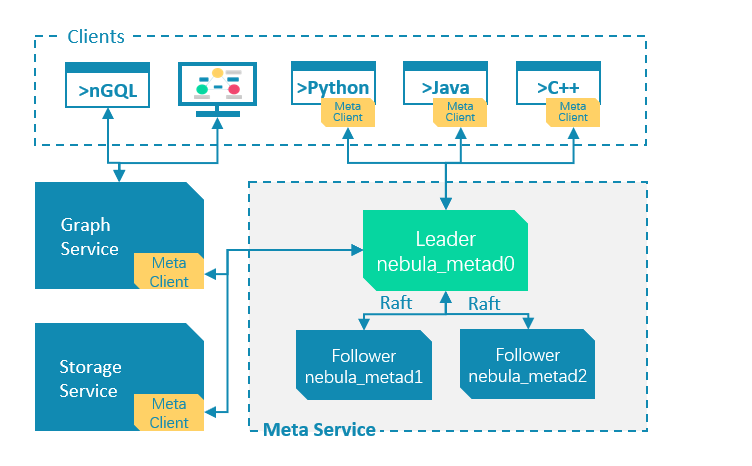
Meta 服务负责元数据管理,例如执行 Graph 服务发送的 Schema 操作请求,管理集群作业、管理用户权限等。Meta 服务基于 Raft 协议保证数据的强一致性。Raft 是一种用于保证多副本一致性的协议,采用多个副本之间竞选的方式,副本如果赢得总副本数中超过一半的投票,就成为 Leader,由 Leader 代表所有副本对外提供服务;其他副本成为 Follower。
Storage
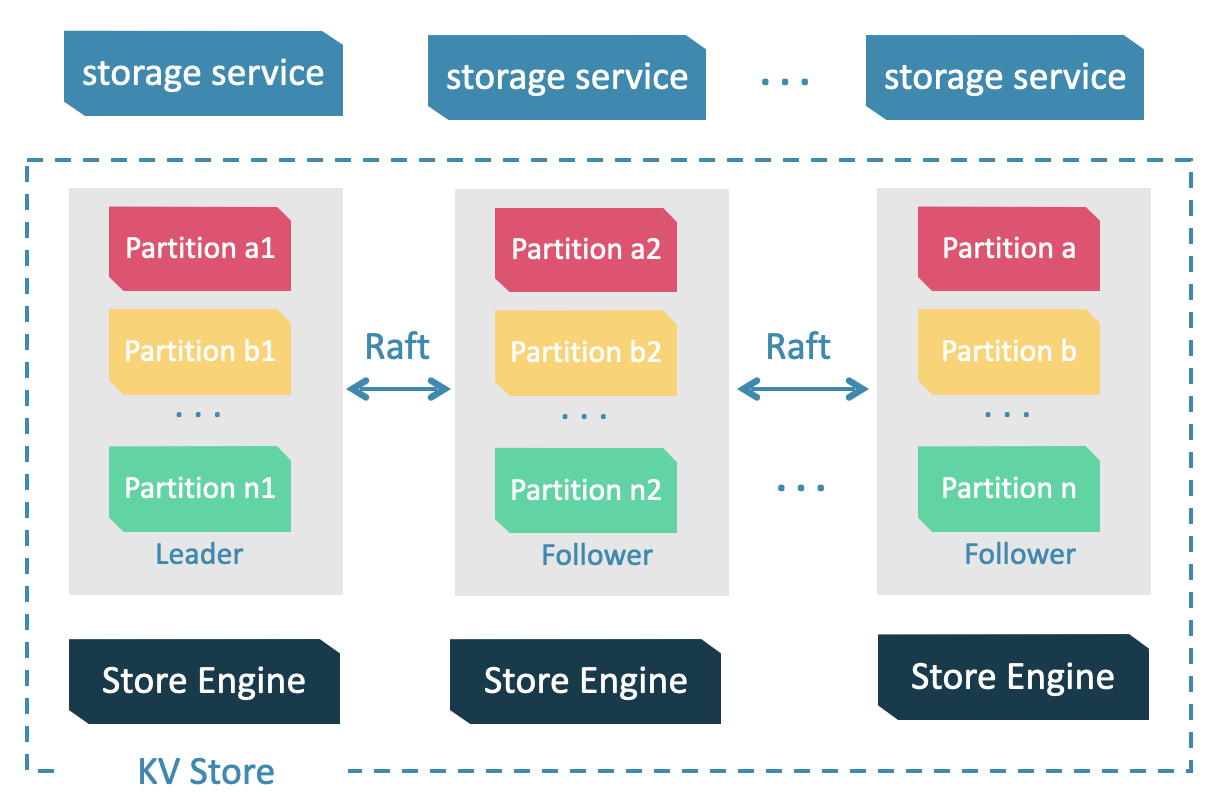
Storage 服务负责存储数据。使用的是自研的 KVStore,基于边切分和高效数据存储格式提供了极高的查询性能。Storage 服务也基于 Raft 协议保证数据的强一致性。
存储格式
接下来重点介绍点和边的存储格式。
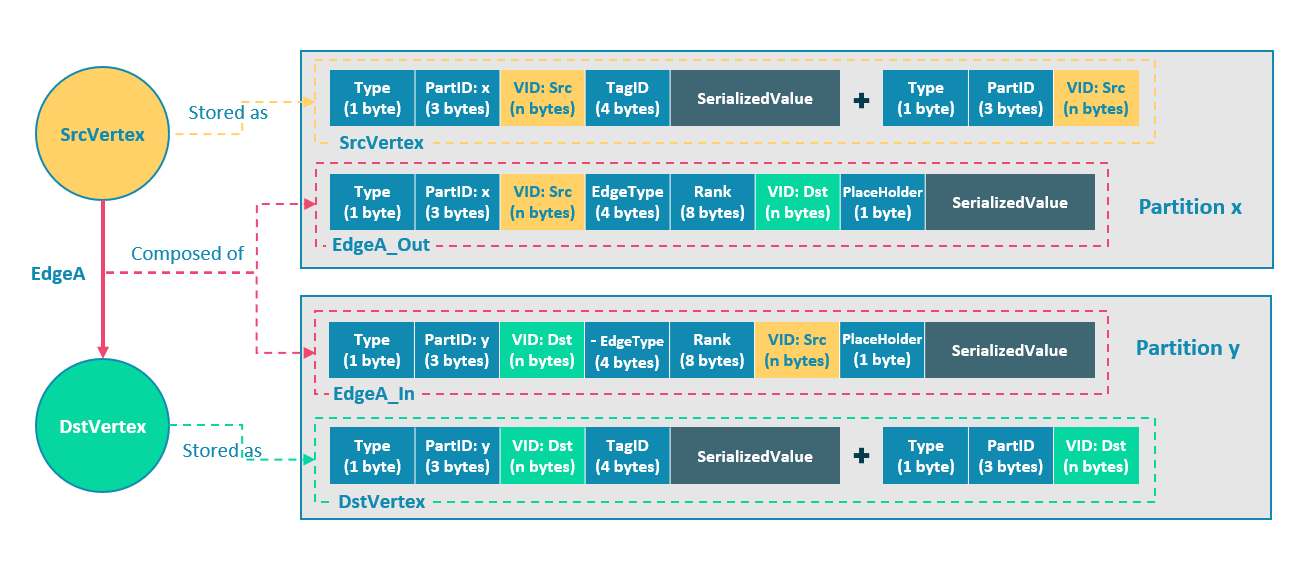
起点或终点的存储格式包含 Key 类型、数据分片编号、点 ID、点关联的 Tag ID,以及序列化的 Value,Value 里保存点的属性信息。为了支持无 Tag 点,还有不包含 Tag ID 和序列化 Value 的 Key。
由于 NebulaGraph 是基于边进行图切分,因此一条边会存储 2 份。与起点存储在相同分片的称为出边,它的格式包含 Key 类型、数据分片编号、起点 ID、边类型、Rank、终点 ID、预留字段,以及序列化的 Value,Value 里保存边的属性信息。
与终点存储在相同分片的称为入边,它的格式与出边几乎一样,只是调换了起点 ID 和 终点 ID 的位置。这样做的好处是增加了遍历速度。
课堂小测试
1、基于 Raft 协议保证一致性的服务有?