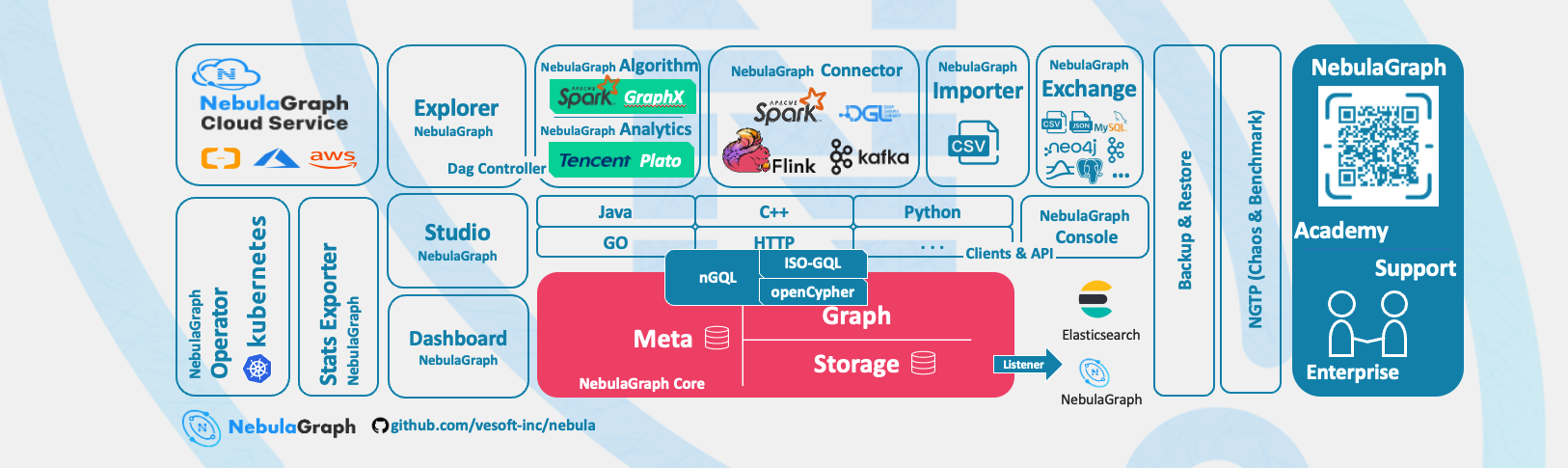
NebulaGraph 概念
什么是 NebulaGraph
NebulaGraph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载包含数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。围绕 NebulaGraph 还有一整套生态工具可以帮助用户方便快捷地使用产品。
NebulaGraph 数据模型
NebulaGraph 可以存储庞大的图形网络并从中检索信息。它可以将图形网络的数据高效地存储为点和边,点代表实体,边代表实体之间的关系,还可以将属性附加到点和边上。NebulaGraph 使用有向属性图模型,即图形网络中的关系是有方向的。作为一个典型的图数据库,可以将丰富的关系通过边及其类型和属性自然地呈现。例如下图,包含图的 6 个基本数据模型:
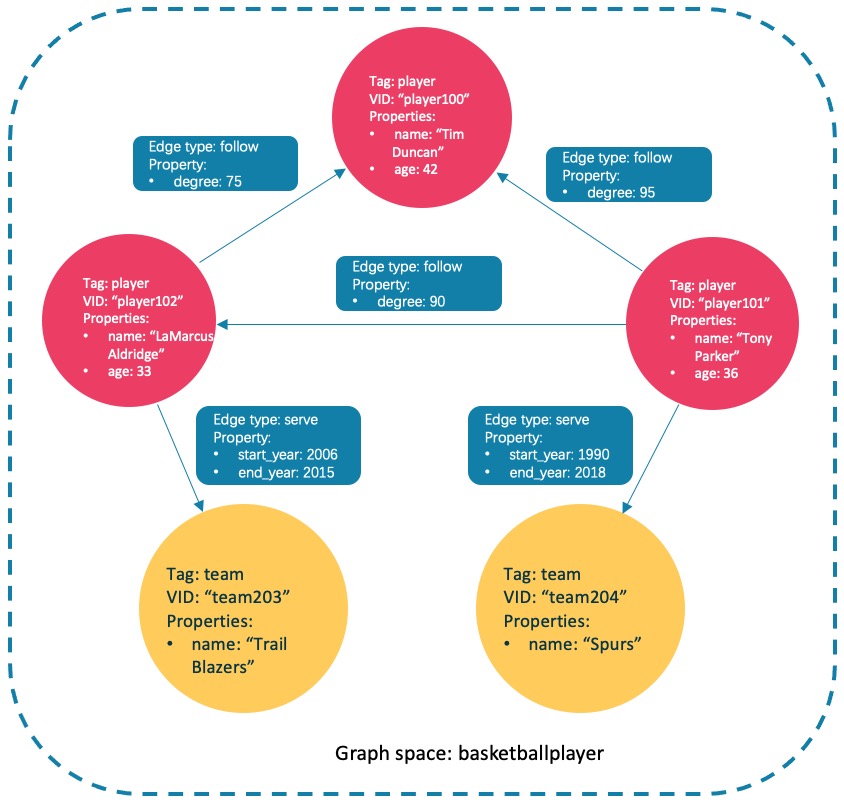
图空间(Space)
图空间用于隔离不同团队或者项目的数据。不同图空间的数据是相互隔离的,可以指定不同的存储副本数、权限、分片等。
点(Vertex)
点用来保存实体对象。标识一个点用的是图空间中唯一的点标识符(VID)。
边(Edge)
边用来连接点,表示两个点之间的关系或行为。标识一条边用的是四元组(起点 VID、边类型、Rank、终点 VID)。其中,Rank 可以用来区分起点、边类型、终点都相同的边。该值完全由用户自己指定。
属性(Property)
属性是指以键值对形式表示的信息。
标签(Tag)
标签由一组事先预定义的属性构成。
边类型(Edge type)
边类型由一组事先预定义的属性构成。
以上 6 个基本的数据模型构成了完整的图形网络。
课堂小测试
1、NebulaGraph 使用的图模型是?